

Buyer queries don’t actually have a working-hours restrict. Nonetheless, think about having the ability to present an on the spot, useful response regardless of the time the shopper asks the query.
That’s the promise of generative AI digital assistants and chatbots – a 24/7 digital concierge.
The AI-powered instrument has taken the load off buyer help groups whereas protecting clients pleased with fast, personalised responses.
But, there’s a plot twist: Whereas firms are going all-in on this know-how, with analysis exhibiting the worldwide chatbot market is predicted to develop from $5.64 billion in 2023 to $16.74 billion by 2028, clients aren’t precisely speeding to embrace it. In truth, 60% of shoppers desire human interplay over chatbots in relation to understanding their wants.
This mismatch suggests we’d must rethink how we strategy and design this know-how. In spite of everything, what good is a revolutionary instrument if folks aren’t able to embrace it?
Prioritizing efficient design methods to unlock the potential of digital assistants
One of many principal explanation why chatbots haven’t but caught on is that they’re largely constructed with out contemplating person expertise. Having a dialog with such a chatbot would imply going by the painful expertise of repeated responses to completely different queries and virtually no contextual consciousness.
Think about your buyer is making an attempt to reschedule a flight for a household emergency, solely to be caught in an countless loop of pre-written responses from the digital assistant asking if you wish to “verify flight standing” or “e-book a brand new flight.” This unhelpful dialog, devoid of the private human contact, would simply drive clients away.
That is the place generative AI or GenAI could rework chatbot interactions and empower your buyer help groups. In contrast to conventional chatbots, which depend on written responses, generative AI fashions can comprehend and grasp person intent, leading to extra personalised and contextually conscious responses.
With the flexibility to generate responses in actual time, a GenAI-powered assistant may acknowledge the urgency of the flight rescheduling request, empathize with the scenario, and seamlessly information the person by the method—skipping irrelevant choices and focusing straight on the duty at hand.
Generative AI additionally has dynamic studying capabilities, which allow digital assistants to change their conduct primarily based on earlier encounters and suggestions. Which means that over time, the AI digital assistant improves its capability to anticipate human wants and supply extra pure help.
With a purpose to totally understand the doable potential of chatbots, you have to go above the mere performance of chatbot providers to develop extra user-friendly, satisfying experiences. Which means that digital assistants deal with client calls for proactively as an alternative of reactively.
We’ll stroll you thru the 5 “gasoline” design rules of making the optimum GenAI interactive digital assistant that can provide help to reply to person queries higher.
1. Gasoline context and suggestions by FRAG in your digital assistant design
As AI fashions grow to be smarter, it depends on gathering the right information to supply correct responses. Retrieval-augmented era (RAG), by its industry-wide adoption, performs an enormous function in offering simply that.
RAG techniques, by exterior retrieval mechanisms, fetch info from related information sources like search engines like google or firm databases that primarily exist outdoors its inside databases. These techniques, coupled with massive language fashions (LLMs), shaped the premise for producing AI-informed responses.
Nonetheless, whereas RAG has definitely improved the standard of solutions through the use of related information, it struggles with real-time accuracy and huge, scattered information sources. That is the place federated retrieval augmented era (FRAG) may provide help to.
Introducing the brand new frontier: FRAG
FRAG takes the concept behind RAG to the subsequent degree by fixing two main points talked about earlier than. It will probably entry information from completely different, disconnected information sources (referred to as silos) and ensure the info is related and well timed. Federation of information sources is finished by connectors, this enables completely different organizational sources or techniques to share data which is listed for environment friendly retrieval, thus enhancing the contextual consciousness and accuracy of generated responses.
If we had been to interrupt down how FRAG works, it incorporates the next pre-processing steps:
- Federation: That is the info assortment step. Right here, FRAG collects related information from completely different, disparate sources, corresponding to a number of firm databases, with out truly combining the info.
- Chunking: That is the textual content segmentation step. Now the info has been gathered, and the main focus turns into to separate it into small, manageable items that can assist with environment friendly information processing.
- Embedding: That is the semantic coding step. It merely means all these small items of information are became numerical codes that convey their semantic which means. This step is the rationale why a system is ready to shortly discover and retrieve essentially the most related info when producing a response.
Supply: SearchUnify
Now that we’ve coated the fundamentals of how FRAG works. Let’s look into the main points of the way it can additional enhance your GenAI digital assistant’s response with higher contextual info.
Enhancing responses with well timed contextual info
Whenever you enter a question, the AI mannequin doesn’t simply seek for actual matches however tries to seek out a solution that matches the which means behind your query utilizing contextual retrieval.
Contextual retrieval for person queries utilizing vector databases
That is the info retrieval part. It ensures that essentially the most applicable, fact-based content material is obtainable to you for the subsequent step.
A person question is translated to an embedding – a numerical vector that displays the which means behind the query. Think about you seek for “finest electrical vehicles in 2024.” The system interprets this question right into a numerical vector that captures its which means, which isn’t nearly any automotive however particularly about one of the best electrical vehicles and inside the 2024 time-frame.
The question vector is then matched in opposition to a precomputed, listed database of information vectors that signify related articles, critiques, and datasets about electrical vehicles. So, if there are critiques of various automotive fashions within the database, the system retrieves essentially the most related information fragments—like particulars on one of the best electrical vehicles launching in 2024—from the database primarily based on how intently they match your question.
Whereas the related information fragments are retrieved primarily based on the similarity match, the system checks for entry management to make sure you are allowed to see that information, corresponding to subscription-based articles. It additionally makes use of an insights engine to customise the outcomes to make them extra helpful. For instance, if you happen to had beforehand regarded for SUVs, the system would possibly prioritize electrical SUVs within the search outcomes, tailoring the response to your preferences.
As soon as the related, custom-made information has been obtained, sanity assessments are carried out. Ought to the obtained information move the sanity verify, it’s despatched to the LLM agent for response era; ought to it fail, retrieval is repeated. Utilizing the identical instance, if a evaluation of an electrical automotive mannequin appears outdated or incorrect, the system would discard it and search once more for higher sources.
Lastly, the retrieved vectors (i.e., automotive critiques, comparisons, newest fashions, and up to date specs) are translated again into human-readable textual content and mixed along with your authentic question. This allows the LLM to supply essentially the most correct outcomes.
Enhanced response era with LLMs
That is the response synthesis part. After the info has been retrieved by vector search, the LLM processes it to generate a coherent, detailed, and customised response.
With contextual retrieval the LLM has a holistic understanding of the person intent, together with factually related info. It understands that the reply you’re searching for isn’t about generic info relating to electrical vehicles however particularly providing you with info related to one of the best 2024 fashions.
Now, the LLM processes the improved question, pulling collectively the details about one of the best vehicles and providing you with detailed responses with insights like battery life, vary, and value comparisons. For instance, as an alternative of a generic response like “Tesla makes good electrical vehicles,” you’ll get a extra particular, detailed reply like “In 2024, Tesla’s Mannequin Y presents one of the best vary at 350 miles, however the Ford Mustang Mach-E supplies a extra reasonably priced value level with comparable options.”
The LLM typically pulls direct references from the retrieved paperwork. For instance, the system could cite a particular client evaluation or a comparability from a automotive journal in its response to provide you a well-grounded, fact-based reply. This ensures that the LLM supplies a factually correct and contextually related reply. Now your question about “finest electrical vehicles in 2024” ends in a well-rounded, data-backed reply that helps you make an knowledgeable choice.
Steady studying and person suggestions
Coaching and sustaining an LLM isn’t all that straightforward. It may be each time consuming and useful resource intensive. Nonetheless, the great thing about FRAG is that it permits for steady studying. With adaptive studying strategies, corresponding to human-in-the-loop, the mannequin repeatedly learns from new information accessible both from up to date data bases or suggestions from previous person interactions.
So, over time, this improves the efficiency and accuracy of the LLM. Consequently, your chatbot turns into extra able to producing solutions related to the person’s query.
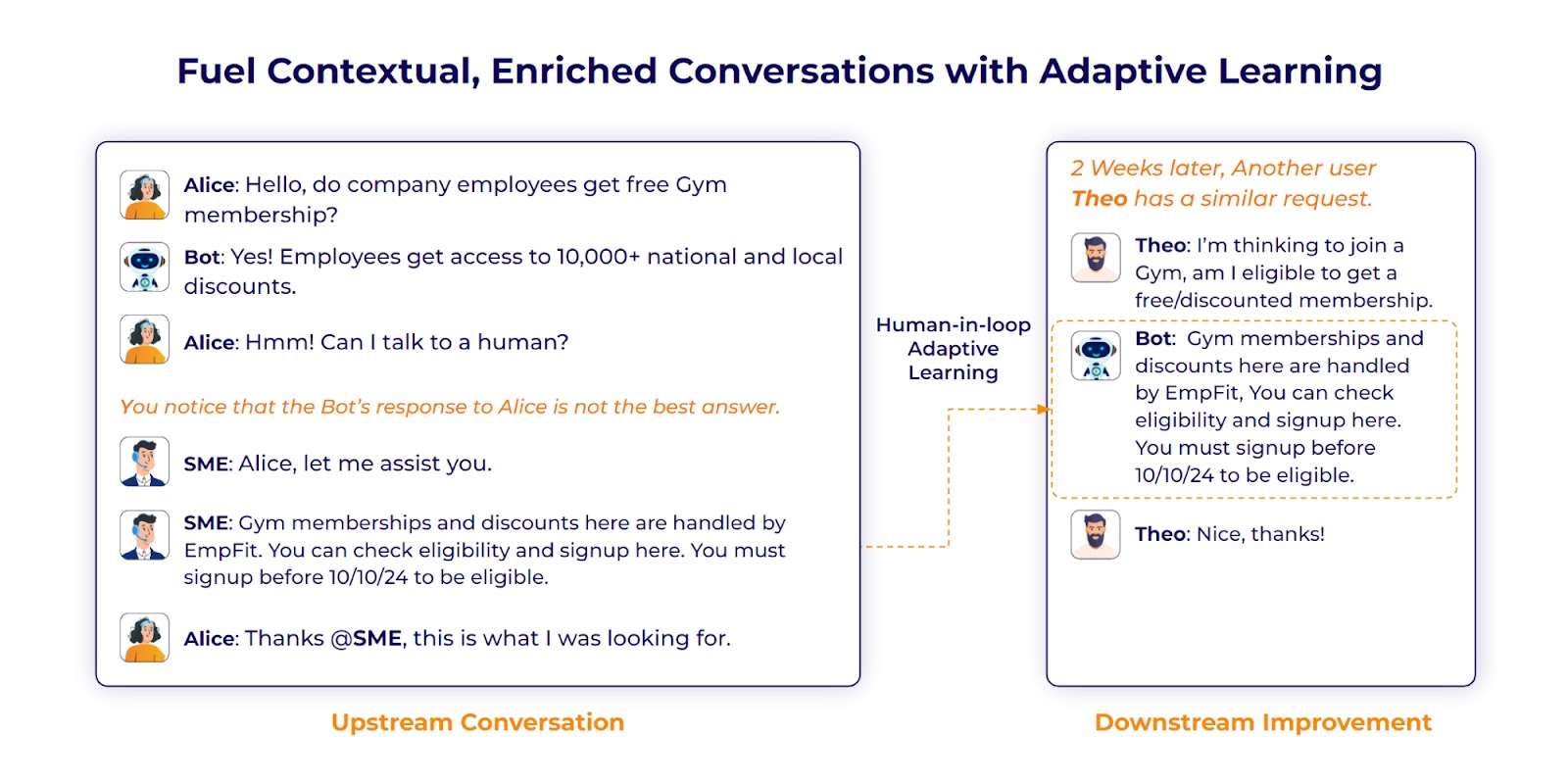
Supply: SearchUnify
2. Gasoline person confidence and conversations with generative fallback in your digital assistant design
Having a generative fallback mechanism is crucial when you’re engaged on designing your digital assistant.
How does it assist?
When your digital assistant can’t reply a query utilizing the principle LLM, the fallback mechanism will permit it to retrieve info from a data base or a particular fallback module created to supply a backup response. This ensures that your person will get help even when the first LLM is unable to supply a solution, serving to stop the dialog from breaking down.
If the fallback system additionally can not assist with the person’s question, the digital assistant may escalate it to a buyer help consultant.
For instance, think about you’re utilizing a digital assistant to e-book a flight, however the system would not perceive a particular query about your baggage allowance. As an alternative of leaving you caught, the assistant’s fallback mechanism kicks in and retrieves details about baggage guidelines from its backup data base. If it nonetheless can’t discover the best reply, the system shortly forwards your question to a human agent who can personally assist you determine your baggage choices.
This hybrid strategy with automated and human assistance will end in your customers receiving quicker responses leaving happy clients.
3. Gasoline person expertise with reference citations in your digital assistant design
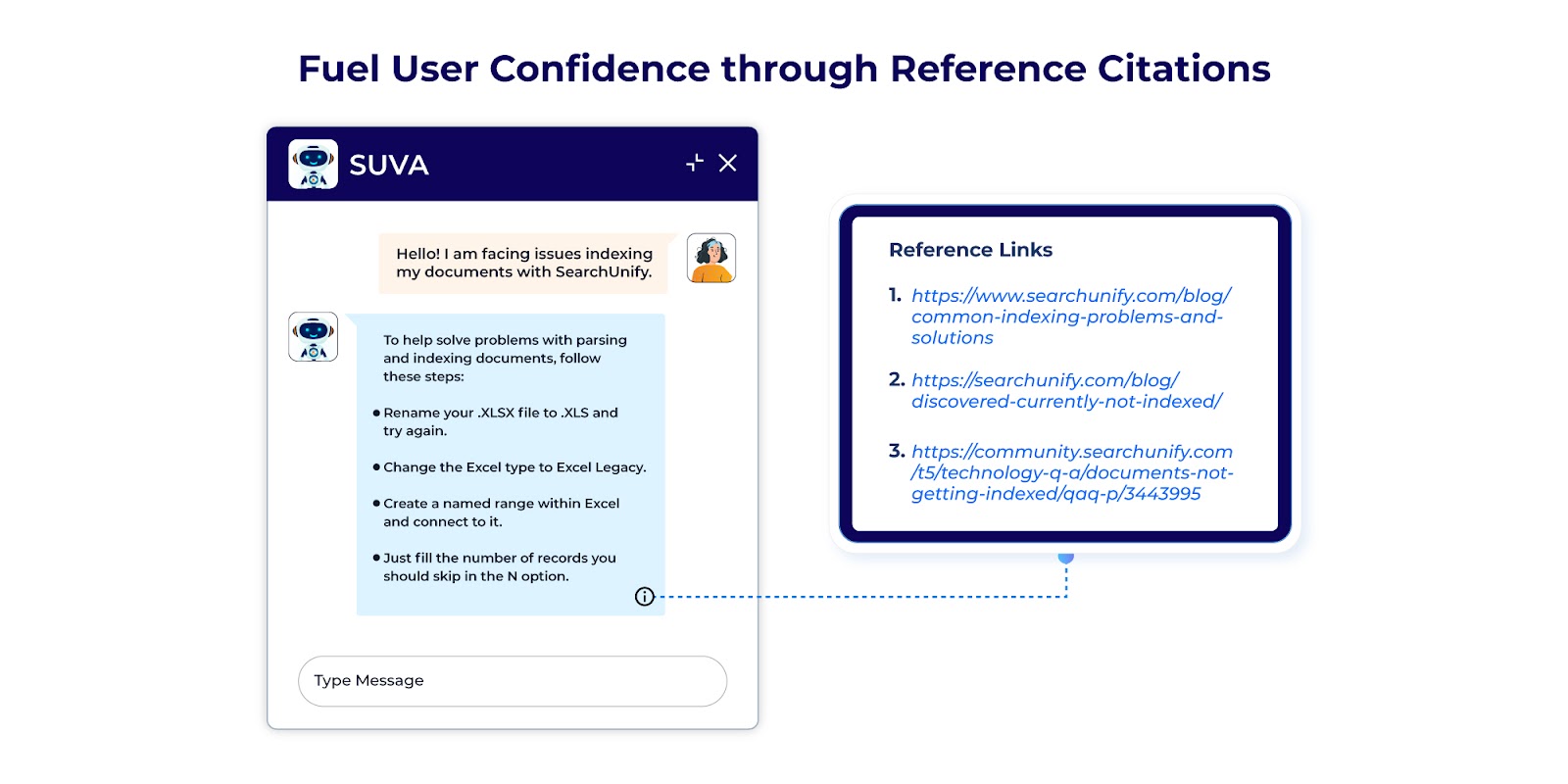
Together with reference citations when designing your digital assistants will assist you to enhance belief amongst your customers in relation to the solutions delivered.
Transparency is on the core of person belief. So offering these reference citations goes a good distance in fixing the dilemma that LLMs ship solutions which might be unproven. Now your digital assistant’s solutions will probably be backed by sources which might be traceable and verifiable.
Your chatbot can share related paperwork or sources of knowledge it is determined by when producing the responses with the person. This is able to shed gentle for the person on the context and reasoning behind the reply whereas permitting them to cross-validate the data. This additionally offers the added bonus of permitting the person to dig deeper into the data if they need to take action.
With reference citations in your design, you may concentrate on the continual enchancment of your digital assistant. This transparency would assist with figuring out any errors within the solutions supplied. For instance, if a chatbot tells a person, “I retrieved this reply primarily based on a doc from 2022,” however the person realizes that this info is outdated, they’ll flag it. The chatbot’s system can then be adjusted to make use of newer information in future responses. Any such suggestions loop enhances the chatbot’s general efficiency and reliability.
4. Gasoline fine-tuned and personalised conversations in your digital assistant design
When designing a chatbot, you have to perceive that there’s worth in making a constant persona.
Whereas personalizing conversations ought to be high of thoughts when designing a chatbot, you also needs to guarantee its persona is clearly outlined and constant. It will assist your person perceive what the digital assistant can and can’t do.
Setting this upfront will assist you to outline your buyer’s expectiations and permit your chatbot to simply meet them, enhancing buyer expertise. Make certain the chatbot’s persona, tone, and magnificence correspond with person expectations to attain confidence and predictability when it engages along with your buyer.
Management conversations by temperature and immediate injection
The best design of a digital assistant reveals a mixture of convergent and divergent concepts. The convergent design ensures readability and accuracy in response by searching for a well-defined resolution to an issue. The divergent design promotes innovation and inquiry in addition to a number of doable solutions and concepts.
In digital assistant design, temperature management and immediate injection match into each convergent and divergent design processes. Temperature management can dictate whether or not the chatbot leans in the direction of a convergent or divergent design primarily based on the set worth, whereas immediate injection can form how structured or open-ended the responses are, influencing the chatbot’s design stability between accuracy and creativity.
Temperature management in chatbot design
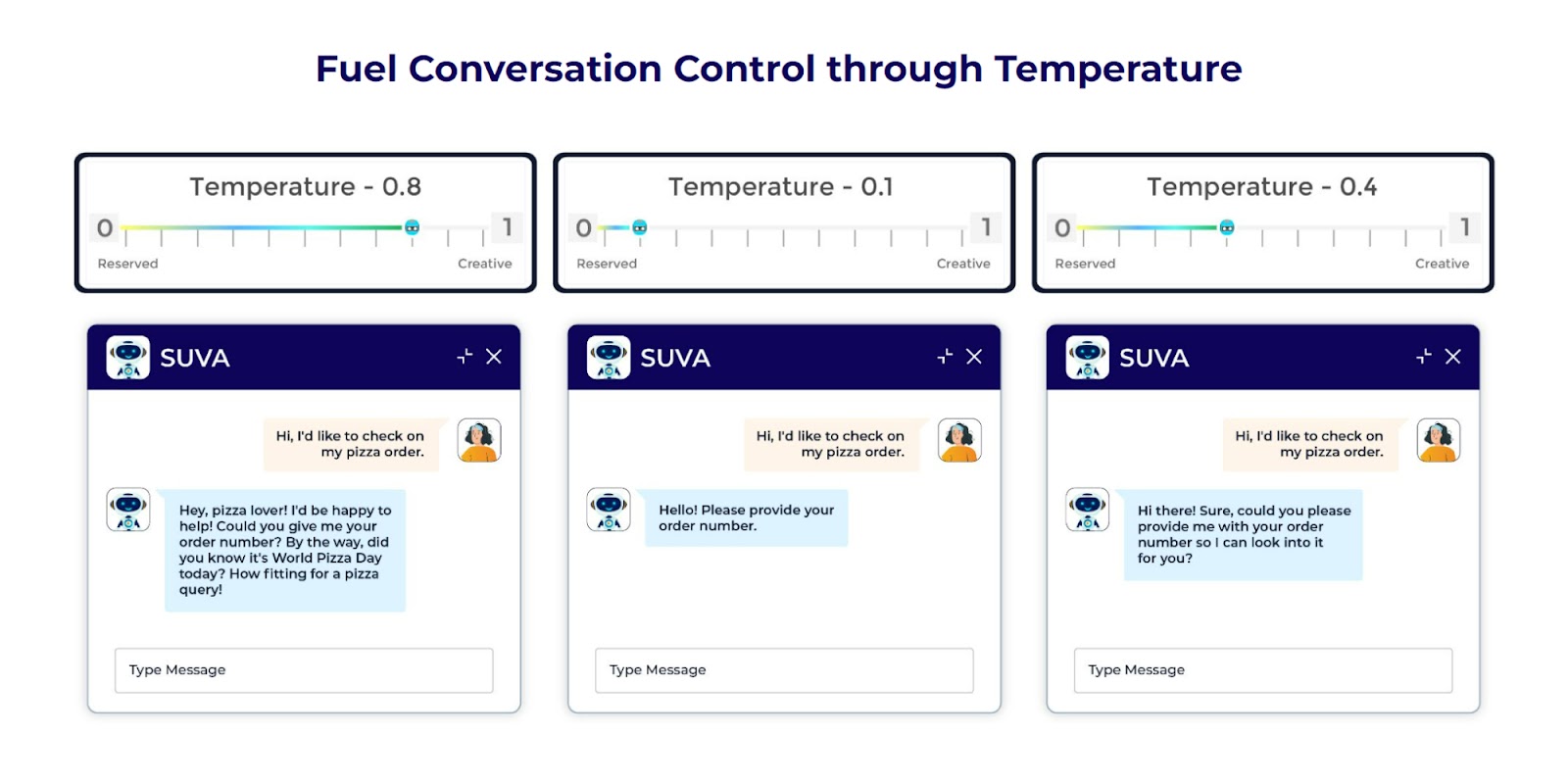
Temperature management is a strategy to govern the originality and randomness of your chatbot. Its function is to control variation and creativity within the produced outputs by a language mannequin.
Let’s focus on temperature management’s results on chatbot efficiency in addition to its mechanisms.
With regards to performance, a temperature between 0.1 and 1.0 is employed ideally as a pointer within the LLM utilized in a chatbot design. A decrease temperature close to 0.1 will push the LLM towards cautious replies that are extra consistent with the person immediate and data base obtained info. Much less doubtless so as to add shocking options, the solutions will probably be extra factual and reliable.
Alternatively, a better temperature – that which approaches 1.0 – helps the LLM generate extra authentic and attention-grabbing solutions. Thus, integrating the ingenious points of the chatbot, which presents much more varied responses from the given immediate, enormously helps to supply a way more human-like and dynamic dialog. However with extra inventiveness comes the potential of factual errors or pointless info.
What are the benefits? Temperature management enables you to fastidiously match your chatbot’s reply model to the type of scenario. For factual analysis, for example, accuracy may take entrance stage, and you’ll want a decrease temperature. Artistic inspiration by way of “immersive storytelling” or problem-solving capability requires a better temperature.
This management will permit for temperature change as per person inclination and context to make your chatbot’s reply extra pertinent and interesting. Folks searching for thorough data would worth easy solutions, whereas shoppers searching for distinctive content material would admire inventiveness.
What are the concerns to bear in mind?
- Stability: It needs to be at an appropriate degree since excessively imaginative solutions may show ineffective or misleading, whereas very conservative solutions sound boring and uninspired. The proper stability would allow replies to be actual and intriguing.
- Context: What the person anticipated from this chat and whether or not they meant to make the most of their system for something particular or normal would decide the temperature worth. Decrease temperatures are extra suited to extremely dependable responses with excessive accuracy, whereas greater temperatures could possibly be higher for open-ended or artistic discussions.
- Process-specific modifications: To make the chatbots environment friendly, an environment friendly temperature needs to be decided primarily based on the actual activity. Whereas a better temperature would allow artistic, diverse ideas throughout brainstorming, a low temperature ensures easy responses to technical help issues.
By together with these strategies in your chatbot design, you assure a well-rounded strategy that balances dependability with creativity to supply a really perfect person expertise custom-made to completely different settings and preferences.
Supply: SearchUnify
Immediate injection
Experimenting with a number of stimuli to enhance and improve the efficiency of a digital assistant is among the many most essential issues you are able to do.
You possibly can experimentally change the prompts to enhance the relevance and efficacy of your conversational synthetic intelligence system.
Here’s a methodical, organized strategy to play about along with your prompts.
- Testing the prompts: Create a number of prompts reflecting completely different person intent and conditions. It will provide help to perceive how varied stimuli have an effect on the digital assistant’s efficiency. To ensure thorough protection, assessments ought to use normal searches and likewise strive edge eventualities. It will spotlight doable weak areas and present how successfully the mannequin reacts to completely different inputs.
- Iterate relying on output values: Study the output from the immediate on relevancy, correctness, and high quality. Moreover, observe patterns or discrepancies within the responses that time out areas that want work. Based mostly on what you discover from the observations, make repeated modifications to the language, group, and specificity of the questions. It is a strategy of enchancment by way of a number of phases whereby the phrasing, group, and specificity of the prompts are enhanced to raised meet anticipated outcomes. They keep context-specific inside the mannequin and often assist to fine-tune cues in order that there are much more actual responses.
- Overview efficiency: Consider the chatbot’s efficiency throughout quite a few parameters corresponding to reply accuracy, relevance, person pleasure, and levels of involvement utilizing many stimuli. Approaches used embody qualitative and quantitative ones, together with person feedback, mistake charges, and benchmark comparability research. This evaluation part factors up areas for improvement and provides particulars on the chatbot’s capability to fulfill your end-user expectations.
- Enhance the mannequin: The outcomes of the evaluation and feedback will provide help to to enhance the efficiency of your chatbot mannequin. That might entail retuning the mannequin with improved information, adjusting the parameters of your mannequin, or together with extra circumstances into coaching to create workarounds for points noticed. Positive-tuning seeks to supply wonderful responses and make the chatbot receptive to many cues. A conversational synthetic intelligence system will probably be extra sturdy and environment friendly the extra exactly it’s tuned relying on methodical testing.
5. Gasoline price effectivity by managed retrieval in your digital assistant design
Semantic search is the subtle info retrieval strategy that makes use of pure language fashions to enhance consequence relevance and precision, which we now have talked about earlier than.
In contrast to a conventional keyword-based search, which is principally primarily based on match, search semantics retains person queries in thoughts primarily based on the which means and context they’re asking. It retrieves info primarily based on what an individual would possibly need to seek for – the underlying intent and conceptual relevance as an alternative of straightforward key phrase occurrences.
How semantic search works
Semantic search techniques use advanced algorithms and fashions that analyze context and nuances in your person queries. Since such a system can perceive what phrases and phrases imply inside a broader context, it may possibly determine and return related content material if the precise key phrases have not been used.
This allows more practical retrieval of knowledge consistent with the person’s intent, thus returning extra correct and significant outcomes.
Advantages of semantic search
The advantages of semantic search embody:
- Relevance: Semantic search considerably improves relevance since retrieval is now extra conceptual, counting on the which means of issues slightly than string matching. In essence, which means that the outcomes returned might be far more related to a person’s wants and questions and might be responded to or higher answered.
- Effectivity: Retrieving solely related info reduces the quantity of information processed and analyzed by the language mannequin engaged. Focused retrieval minimizes irrelevant content material, which will help streamline the interplay course of, thereby enhancing the system’s effectivity. Your customers can now entry related info quicker.
- Value effectiveness: Semantic search will probably be price efficient as a result of it saves tokens and computational assets. With semantic search, irrelevant information processing or dealing with is prevented resulting from relevance-based content material retrieval. With this side, the variety of response tokens consumed will probably be minimal with a lesser computational load on the language mannequin occurring. Therefore, organizations can obtain vital price financial savings relating to ideally suited high quality outputs within the search outcomes.
Paving the way in which for smarter, user-centric digital assistants
To beat the statistics of 60% of shoppers preferring human interplay over chatbots includes a considerate design technique and understanding all of the underlying issues.
With a fine-tuned and personalised design strategy to your digital assistant, your organization will gasoline person confidence with one breakdown-free and correct response at a time.
Interested by how voice know-how is shaping the way forward for digital assistants? Discover our complete information to know the inside workings and prospects of voice assistants.
Edited by Shanti S Nair
{kind=link}