

Editor’s word: This text, initially printed on Nov. 15, 2023, has been up to date.
To know the most recent developments in generative AI, think about a courtroom.
Judges hear and determine circumstances primarily based on their basic understanding of the regulation. Generally a case — like a malpractice go well with or a labor dispute — requires particular experience, so judges ship court docket clerks to a regulation library, searching for precedents and particular circumstances they’ll cite.
Like a great decide, giant language fashions (LLMs) can reply to all kinds of human queries. However to ship authoritative solutions — grounded in particular court docket proceedings or comparable ones — the mannequin must be supplied that data.
The court docket clerk of AI is a course of known as retrieval-augmented era, or RAG for brief.
How It Bought Named ‘RAG’
Patrick Lewis, lead writer of the 2020 paper that coined the time period, apologized for the unflattering acronym that now describes a rising household of strategies throughout a whole lot of papers and dozens of economic companies he believes signify the way forward for generative AI.
“We positively would have put extra thought into the title had we recognized our work would turn out to be so widespread,” Lewis mentioned in an interview from Singapore, the place he was sharing his concepts with a regional convention of database builders.
“We all the time deliberate to have a nicer sounding title, however when it got here time to jot down the paper, nobody had a greater thought,” mentioned Lewis, who now leads a RAG staff at AI startup Cohere.
So, What Is Retrieval-Augmented Era (RAG)?
Retrieval-augmented era is a method for enhancing the accuracy and reliability of generative AI fashions with data fetched from particular and related information sources.
In different phrases, it fills a spot in how LLMs work. Below the hood, LLMs are neural networks, sometimes measured by what number of parameters they comprise. An LLM’s parameters primarily signify the final patterns of how people use phrases to type sentences.
That deep understanding, typically known as parameterized information, makes LLMs helpful in responding to basic prompts. Nevertheless, it doesn’t serve customers who need a deeper dive into a particular kind of data.
Combining Inside, Exterior Sources
Lewis and colleagues developed retrieval-augmented era to hyperlink generative AI companies to exterior sources, particularly ones wealthy within the newest technical particulars.
The paper, with coauthors from the previous Fb AI Analysis (now Meta AI), College Faculty London and New York College, known as RAG “a general-purpose fine-tuning recipe” as a result of it may be utilized by almost any LLM to attach with virtually any exterior useful resource.
Constructing Consumer Belief
Retrieval-augmented era provides fashions sources they’ll cite, like footnotes in a analysis paper, so customers can test any claims. That builds belief.
What’s extra, the method may also help fashions clear up ambiguity in a person question. It additionally reduces the chance {that a} mannequin will give a really believable however incorrect reply, a phenomenon known as hallucination.
One other nice benefit of RAG is it’s comparatively simple. A weblog by Lewis and three of the paper’s coauthors mentioned builders can implement the method with as few as 5 strains of code.
That makes the strategy sooner and cheaper than retraining a mannequin with further datasets. And it lets customers hot-swap new sources on the fly.
How Individuals Are Utilizing RAG
With retrieval-augmented era, customers can primarily have conversations with information repositories, opening up new sorts of experiences. This implies the purposes for RAG could possibly be a number of occasions the variety of out there datasets.
For instance, a generative AI mannequin supplemented with a medical index could possibly be an excellent assistant for a health care provider or nurse. Monetary analysts would profit from an assistant linked to market information.
In truth, nearly any enterprise can flip its technical or coverage manuals, movies or logs into sources known as information bases that may improve LLMs. These sources can allow use circumstances corresponding to buyer or discipline help, worker coaching and developer productiveness.
The broad potential is why firms together with AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG.
Getting Began With Retrieval-Augmented Era
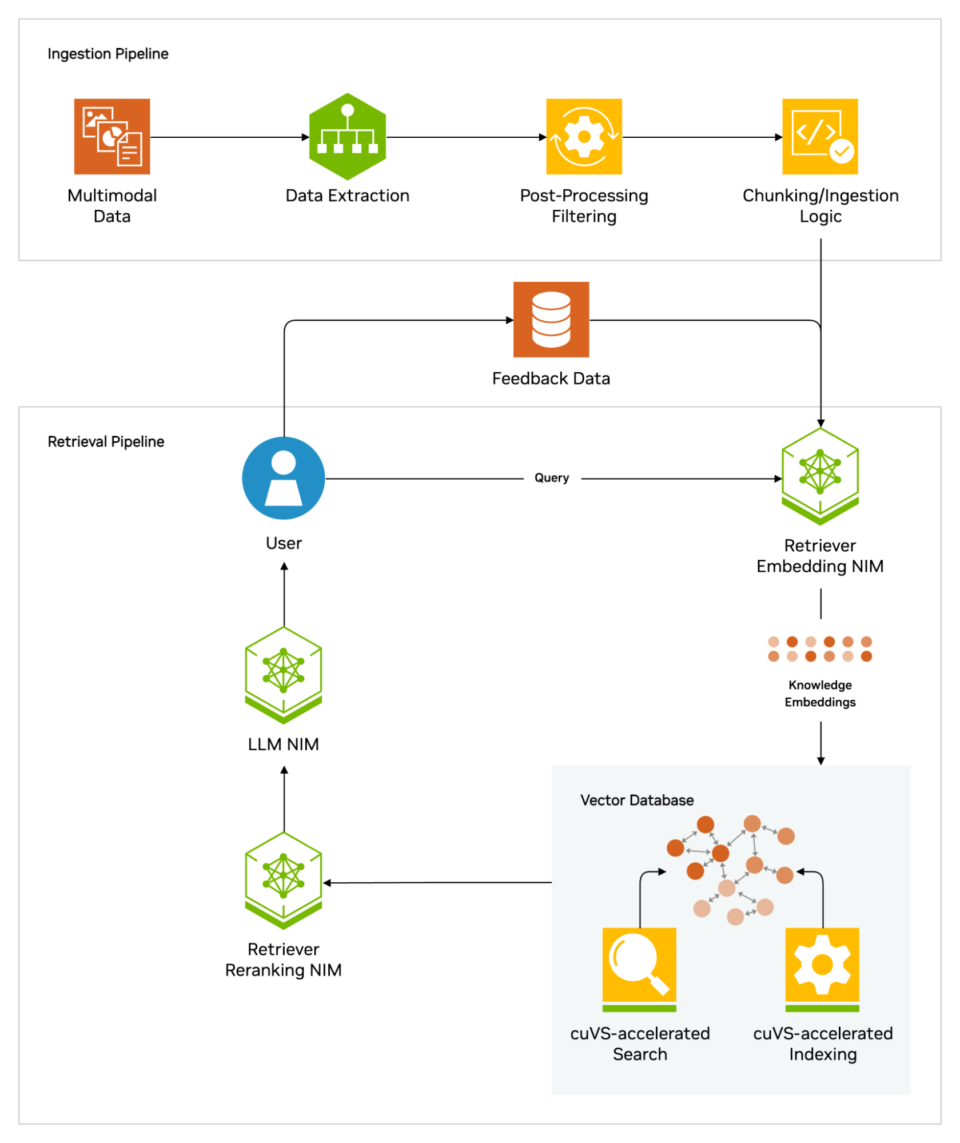
The NVIDIA AI Blueprint for RAG helps builders construct pipelines to attach their AI purposes to enterprise information utilizing industry-leading know-how. This reference structure supplies builders with a basis for constructing scalable and customizable retrieval pipelines that ship excessive accuracy and throughput.
The blueprint can be utilized as is, or mixed with different NVIDIA Blueprints for superior use circumstances together with digital people and AI assistants. For instance, the blueprint for AI assistants empowers organizations to construct AI brokers that may rapidly scale their customer support operations with generative AI and RAG.
As well as, builders and IT groups can attempt the free, hands-on NVIDIA LaunchPad lab for constructing AI chatbots with RAG, enabling quick and correct responses from enterprise information.
All of those sources use NVIDIA NeMo Retriever, which supplies main, large-scale retrieval accuracy and NVIDIA NIM microservices for simplifying safe, high-performance AI deployment throughout clouds, information facilities and workstations. These are supplied as a part of the NVIDIA AI Enterprise software program platform for accelerating AI improvement and deployment.
Getting the perfect efficiency for RAG workflows requires huge quantities of reminiscence and compute to maneuver and course of information. The NVIDIA GH200 Grace Hopper Superchip, with its 288GB of quick HBM3e reminiscence and eight petaflops of compute, is right — it could possibly ship a 150x speedup over utilizing a CPU.
As soon as firms get acquainted with RAG, they’ll mix quite a lot of off-the-shelf or customized LLMs with inside or exterior information bases to create a variety of assistants that assist their staff and prospects.
RAG doesn’t require a knowledge middle. LLMs are debuting on Home windows PCs, due to NVIDIA software program that allows all types of purposes customers can entry even on their laptops.
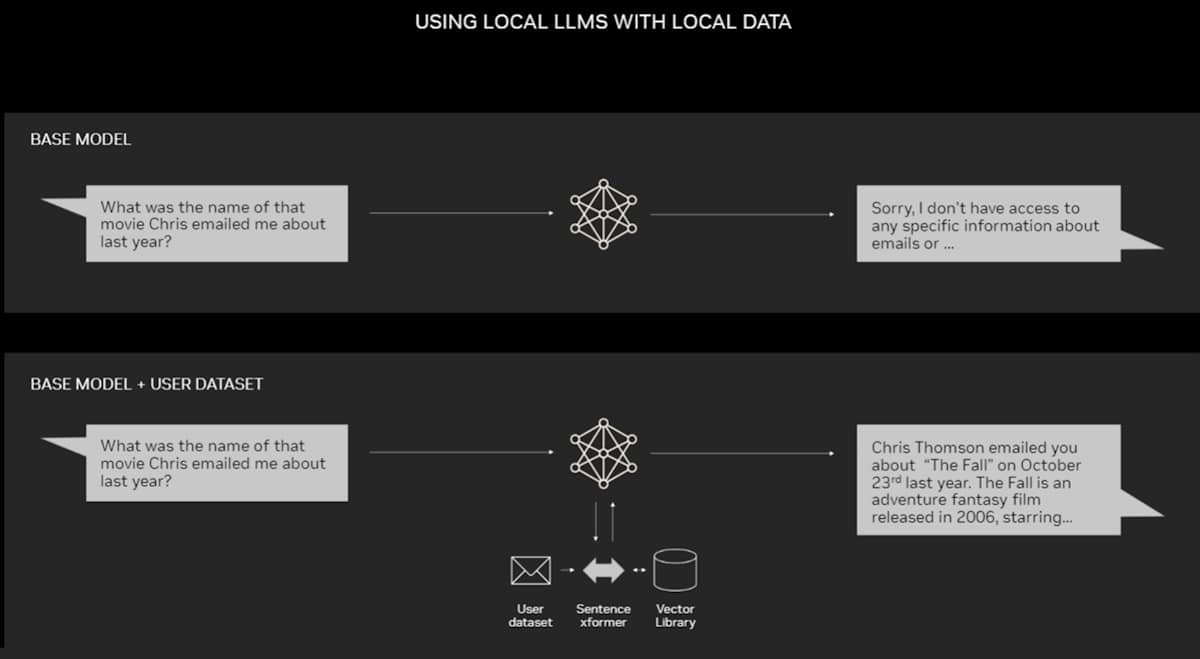
PCs geared up with NVIDIA RTX GPUs can now run some AI fashions regionally. By utilizing RAG on a PC, customers can hyperlink to a non-public information supply – whether or not that be emails, notes or articles – to enhance responses. The person can then really feel assured that their information supply, prompts and response all stay personal and safe.
A current weblog supplies an instance of RAG accelerated by TensorRT-LLM for Home windows to get higher outcomes quick.
The Historical past of RAG
The roots of the method return a minimum of to the early Seventies. That’s when researchers in data retrieval prototyped what they known as question-answering techniques, apps that use pure language processing (NLP) to entry textual content, initially in slender subjects corresponding to baseball.
The ideas behind this sort of textual content mining have remained pretty fixed through the years. However the machine studying engines driving them have grown considerably, rising their usefulness and recognition.
Within the mid-Nineties, the Ask Jeeves service, now Ask.com, popularized query answering with its mascot of a well-dressed valet. IBM’s Watson turned a TV movie star in 2011 when it handily beat two human champions on the Jeopardy! recreation present.
Right now, LLMs are taking question-answering techniques to an entire new stage.
Insights From a London Lab
The seminal 2020 paper arrived as Lewis was pursuing a doctorate in NLP at College Faculty London and dealing for Meta at a brand new London AI lab. The staff was trying to find methods to pack extra information into an LLM’s parameters and utilizing a benchmark it developed to measure its progress.
Constructing on earlier strategies and impressed by a paper from Google researchers, the group “had this compelling imaginative and prescient of a educated system that had a retrieval index in the course of it, so it may be taught and generate any textual content output you needed,” Lewis recalled.

When Lewis plugged into the work in progress a promising retrieval system from one other Meta staff, the primary outcomes had been unexpectedly spectacular.
“I confirmed my supervisor and he mentioned, ‘Whoa, take the win. This type of factor doesn’t occur fairly often,’ as a result of these workflows might be arduous to arrange accurately the primary time,” he mentioned.
Lewis additionally credit main contributions from staff members Ethan Perez and Douwe Kiela, then of New York College and Fb AI Analysis, respectively.
When full, the work, which ran on a cluster of NVIDIA GPUs, confirmed learn how to make generative AI fashions extra authoritative and reliable. It’s since been cited by a whole lot of papers that amplified and prolonged the ideas in what continues to be an energetic space of analysis.
How Retrieval-Augmented Era Works
At a excessive stage, right here’s how retrieval-augmented era works.
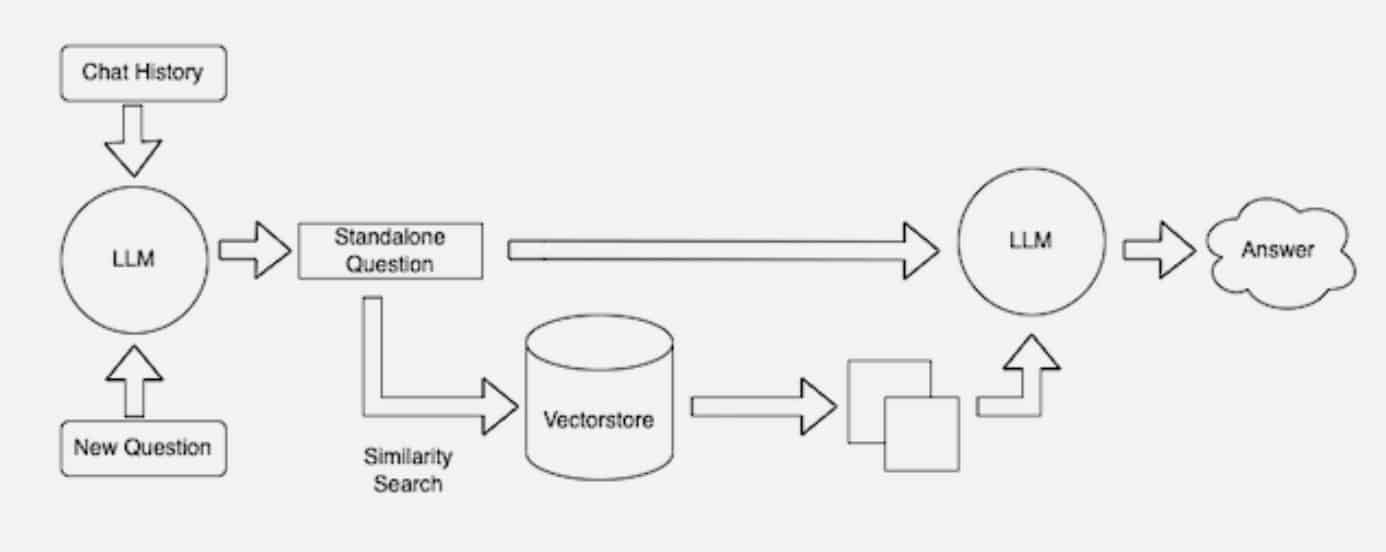
When customers ask an LLM a query, the AI mannequin sends the question to a different mannequin that converts it right into a numeric format so machines can learn it. The numeric model of the question is usually known as an embedding or a vector.
The embedding mannequin then compares these numeric values to vectors in a machine-readable index of an out there information base. When it finds a match or a number of matches, it retrieves the associated information, converts it to human-readable phrases and passes it again to the LLM.
Lastly, the LLM combines the retrieved phrases and its personal response to the question right into a ultimate reply it presents to the person, doubtlessly citing sources the embedding mannequin discovered.
Holding Sources Present
Within the background, the embedding mannequin repeatedly creates and updates machine-readable indices, typically known as vector databases, for brand new and up to date information bases as they turn out to be out there.
Many builders discover LangChain, an open-source library, might be notably helpful in chaining collectively LLMs, embedding fashions and information bases. NVIDIA makes use of LangChain in its reference structure for retrieval-augmented era.
The LangChain group supplies its personal description of a RAG course of.
The way forward for generative AI lies in agentic AI — the place LLMs and information bases are dynamically orchestrated to create autonomous assistants. These AI-driven brokers can improve decision-making, adapt to advanced duties and ship authoritative, verifiable outcomes for customers.
{kind=link}